
Testing-Strategie: Welche Tests wann laufen sollten und warum
Eine gute Testing-Strategie braucht ein klares Fundament: Gemeinsame Begriffe, saubere Grenzen zwischen Testarten und einen realistischen Plan, wann welche Tests laufen. Ohne ein solides Fundament entstehen schnell Missverständnisse darüber, welcher Test welche Aufgabe erfüllt. Das führt zu instabilen Tests und am Ende explodieren die Pipeline-Laufzeiten genau dann, wenn du eigentlich schnelle Feedback-Loops brauchst.
In diesem Beitrag bekommst du ein gemeinsames Vokabular, eine Priorisierung der Testtypen und einen praxisorientierten Fahrplan für .NET- und Web-Projekte.
Warum du überhaupt testest
Testing ist in der Praxis vor allem Risikomanagement. Du willst Regressionen vermeiden, sicher refactoren können und Releases mit Sicherheit durchführen. Das funktioniert nur, wenn Tests dir schnell und verlässlich Feedback geben, und zwar so früh wie möglich.
Die Kostenkurve zeigt es klar: Ein Bug, der in einem Unit-Test auffällt, kostet dich meistens Sekunden oder Minuten. Derselbe Bug als UI-Test-Fehler (oder erst in Produktion) kostet schnell Stunden, erzeugt Kontextwechsel und bindet oft mehrere Rollen (Dev, QA, Ops, PO) zur Abstimmung.
Eine Testing-Strategie ist deshalb mehr als einzelne Tests. Sie ist ein Vertrag im Team: Welche Testtypen gibt es? Was darf ein Test? Welche Abhängigkeiten sind ok? Und wann laufen welche Tests? Die Microsoft-Übersicht Testing in .NET beschreibt die wichtigsten Testarten gut. Die eigentliche Arbeit besteht darin, daraus teamtaugliche Regeln abzuleiten.
Test-Landkarte: Testtypen, Scope, Laufzeit und wann sie laufen
Die klassische Testpyramide (viele schnelle Tests unten, wenige teure Tests oben) ist nicht falsch, aber die Realität ist etwas unordentlicher. Moderne Systeme haben mehrere Grenzen: Datenbank, Queue, externe Services, Browser, Mobile. Darum lohnt sich eine Landkarte, die Testtypen nicht nur nach Unit vs. E2E, sondern nach Scope und Trigger sortiert.
Hier ist eine pragmatische Arbeitsdefinition, die sich mit dem deckt, was du in der Praxis in .NET- und Web-Stacks brauchst:
| Testtyp | Scope | Dependencies | Typische Laufzeit | Trigger |
|---|---|---|---|---|
| Unit Tests | kleinste fachlich sinnvolle Einheit | keine echte IO (DB, Filesystem, Netzwerk, Zeit) | ms | lokal, PR |
| Integration Tests | mehrere Komponenten innerhalb der App | Infrastruktur kann echt sein (kontrolliert) | s–min | Nightly, Post-Deployment |
| Contract Tests | Schnittstelle Consumer/Provider (z.B. Web API) | Infrastruktur kann echt sein (kontrolliert) | s–min | Nightly, Post-Deployment |
| Smoke Tests | minimaler ist das System grundsätzlich ok? | echte Umgebung | Sekunden | Post-Deployment gate |
| UI Tests | wenige kritische Journeys | echte Umgebung + stabile Testdaten | min | Post-Deployment, ggf. Nightly |
| Non-Functional | Performance, Security, Architektur | abhängig vom Typ | min–h | on-demand, Nightly/Weekly |
Wichtig ist weniger die perfekte Taxonomie, sondern dass ihr im Team die Begriffe gleich verwendet. Integration Tests sind dabei ein Klassiker: Testet ihr nur gegen eine echte DB, oder auch gegen externe Services? Testet ihr nur innerhalb der App, oder auch über Service-Grenzen hinweg? Klärt solche Fragen früh. In unserem Fall haben wir uns dafür entschieden, dass Integration Tests mehrere Komponenten innerhalb der App testen, während Contract Tests die Schnittstelle zwischen Consumer und Provider (Client und API) abdecken. Damit sind Contract Tests für uns die logische Erweiterung zu Integration Tests, wenn es um APIs geht.
Eine Übersicht ohne Tool-Details kann so aussehen:
- PR-Validation: immer Unit Tests, optional sehr kurzer Smoke (z.B. App startet).
- Nightly: Integration und Contract breiter, plus Security-Scans.
- Post-Deployment: Smoke + wenige UI-Journeys (Happy Path), plus kritische Integration und Contract Tests.
- On-demand: Performance/Load Tests, wenn es ein konkretes Risiko oder Ziel gibt.
Oft hilft es auch, Tests innerhalb eines Testtyps zu priorisieren. So kannst du bei Integration Tests z.B. einen kleinen Smoke-Subset definieren, der beim Post-Deployment läuft. Den vollen Satz führst du nur im Nightly Build aus oder parallel, während das Deployment zur nächsten Stage schon läuft.
Wenn du Tests selektiv laufen lassen willst, ist dotnet test --filter ein extrem praktischer Hebel. Microsoft beschreibt die Filtermöglichkeiten ausführlich in Run selected unit tests. In der Praxis sind zwei Strategien besonders teamtauglich: Filter nach Projekt/Namespace und Filter nach Markierung.
# Beispiel: Nur Unit-Test-Projekte ausführen (konzeptuell, abhängig von eurer Struktur)
dotnet test --filter "FullyQualifiedName~UnitTests"
# Beispiel: Alles außer Integration ausführen
# (für manche Shells muss das ! escaped werden; siehe Microsoft-Dokumentation)
dotnet test --filter "FullyQualifiedName!~IntegrationTests"Gleiches gilt für andere Test-Frameworks: Schau, wie du Tests markieren und filtern kannst, um gezielt Testtypen zu steuern.
Unit Tests: Fundament für alles
Unit Tests testen die kleinste fachlich sinnvolle Einheit: Business-Regeln, Services, Validierungen, Mapper, einzelne Komponenten. Sie müssen schnell, deterministisch und isoliert sein. Die Eigenschaften guter Unit Tests (fast, isolated, repeatable, self-checking) beschreibt Microsoft sehr klar in den Unit testing best practices.
Der wichtigste Grundsatz: Alles außerhalb der Unit wird ersetzt. Dazu zählen Datenbanken, Dateisystem, Netzwerk und auch die aktuelle Zeit.
Ein minimaler Beispieltest:
public class PriceServiceTests
{
[Fact]
public void GivenVipCustomerAndTimeIsWithinBonusWindow_WhenCalculatingPrice_ThenDiscountIsApplied()
{
var customerRepository = new Mock<ICustomerRepository>();
customerRepository
.Setup(r => r.IsVip("customer-123"))
.Returns(true);
var timeProvider = new Mock<ITimeProvider>();
// Set time to 22:30, within VIP bonus window
timeProvider
.Setup(tp => tp.Now)
.Returns(new DateTime(2026, 1, 27, 22, 30, 0));
var sut = new PriceService(customerRepository.Object, timeProvider.Object);
var price = sut.Calculate("customer-123", basePrice: 100m);
price.Should().Be(90m); // 10% discount for VIP
}
}Im Frontend gibt es oft noch das Konzept von Komponenten-Unit-Tests. Dabei wird nicht nur die Logik, sondern auch das Rendering und Verhalten einer UI-Komponente isoliert getestet. Das Prinzip bleibt gleich: Keine echte IO, alles wird gemockt oder simuliert.
Beim Mocking lohnt es sich, die Begriffe sauber zu halten. Microsoft erklärt die Terminologie (mock, stub, fake) in den Best Practices sehr hilfreich, inklusive dem Hinweis, dass die Begriffe in der Literatur nicht immer konsistent verwendet werden. Wichtig für euch ist: Mocks sind nicht mehr Testing, sondern ein Werkzeug. Das Anti-Pattern ist Implementierungsdetails mocken statt Verhalten zu testen.
Wann laufen Unit Tests? Immer: Lokal ständig und als PR-Validation auf jedem Branch.
Wenn du weitere Guidelines zu Unit Tests in .NET brauchst, findest du hier unseren Post Unit Testing in .NET: Saubere Tests für sauberen Code.
Integration Tests: Mehr als ein Baustein
Integration Tests lösen ein häufiges Missverständnis auf: Integration bedeutet hier nicht automatisch Integration mit fremden Services, sondern mehrere Komponenten innerhalb unserer App arbeiten zusammen.
Die Frage ist dann: Welche Infrastruktur ist echt? Eine pragmatische Antwort:
- Echte Infrastruktur ist ok, wenn sie kontrollierbar und reproduzierbar ist (lokal, Container, Test-DB).
- Externe Systeme mockst du, wenn sie unzuverlässig, teuer oder nicht deterministisch sind.
Gerade bei Datenbanken lohnt sich ein realistischer Blick: EF Core diskutiert sehr offen die Trade-offs zwischen In-Memory, SQLite und echter DB in Choosing a testing strategy. In vielen Projekten ist eine lokale DB (oder Container-DB) weniger schwer, als man denkt. Ein gutes Werkzeug dafür ist Testcontainers for .NET, weil es die Lifecycle-Probleme (Start, Cleanup, Isolation) automatisieren kann.
Wann laufen Integration Tests? Oft als Nightly oder gezielt (z.B. vor einem Release). Wenn sie Teil einer PR-Validation sind, dann nur als sehr kleine, stabile Smoke-Subset, sonst werden PR Validierungen unnötig langsam.
Contract Tests: Damit Services unabhängig bleiben
Contract Tests prüfen die Schnittstelle zwischen Consumer und Provider: Requests/Responses, Status Codes, Schemas, Message Contracts. Das Ziel ist, Änderungen früh zu erkennen, ohne alles neu deployen zu müssen.
Wichtig ist die Abgrenzung: Contract Tests sind nicht dasselbe wie Integration Tests innerhalb einer App. Sie testen die Interaktion zwischen Services. Typische Anwendungsfälle sind Web APIs, Messaging-Systeme oder Third-Party-Integrationen.
Du kannst Contracts unterschiedlich betreiben:
- Consumer-driven: Der Consumer definiert Erwartungen, der Provider verifiziert sie später. Das ist der Klassiker, z.B. mit Pact.
- Provider-driven: Der Provider definiert das Schema (z.B. OpenAPI), Consumer validieren dagegen.
Der Rhythmus ist hier entscheidend. Martin Fowler beschreibt in Contract Test gut, warum Contract Tests nicht unbedingt in jede Deployment-Pipeline müssen: Sie sollten sich am Rhythmus der externen Änderung orientieren (z.B. täglich), und ein Fehlschlag ist oft eher ein Anlass für Kommunikation als ein sofortiger Release-Stopper.
Ein praktischer Tipp: Setze auf das Prinzip Contract by Example. Dabei werden konkrete, repräsentative Beispielanfragen und -antworten als Grundlage für die Contract Tests verwendet. Diese Beispiele dienen als lebende Dokumentation und sorgen dafür, dass alle Beteiligten ein gemeinsames Verständnis der Schnittstelle haben. Stabile Snapshots verhindern, dass sich Testdaten unbemerkt ändern, und machen die Tests nachvollziehbar und robust.
UI Tests & Smoke Tests: Kritische Journeys als Sicherheitsnetz nach Deployments
UI Tests sind teuer, aber sie haben einen Vorteil: Sie prüfen dein System so, wie es Nutzer:innen erleben. Die wichtigste Regel lautet deshalb: Wenige, aber wertvolle Journeys.
Smoke Tests sind noch kleiner. Sie beantworten nur: Ist das System grundsätzlich erreichbar und reagiert es? Typische Checks sind ein Health-Endpoint oder ob das Frontend lädt.
Für UI-Tests ist Playwright ein sehr solides Werkzeug, u.a. wegen Auto-Waiting und Web-First Assertions, die die Flakiness im Vergleich zu Selenium reduzieren.
Wenn du mehrere UI-Tests hast, lohnt sich außerdem ein Page Object Model (POM). Dabei kapselst du Selektoren und wiederkehrende Aktionen pro Seite oder Komponente in eigenen Klassen/Modulen. Deine Tests werden dadurch besser lesbar und weniger anfällig, wenn sich das UI leicht verändert.
using System.Threading.Tasks;
using Microsoft.Playwright;
using Xunit;
public class SmokeTests : IAsyncLifetime
{
private IPlaywright _playwright;
private IBrowser _browser;
public async Task InitializeAsync()
{
_playwright = await Playwright.CreateAsync();
_browser = await _playwright.Chromium.LaunchAsync(new BrowserTypeLaunchOptions { Headless = true });
}
public async Task DisposeAsync()
{
await _browser.CloseAsync();
_playwright.Dispose();
}
[Fact]
public async Task Smoke_HomepageLoadsAndShowsMainHeading()
{
using var context = await _browser.NewContextAsync();
var page = await context.NewPageAsync();
await page.GotoAsync(Environment.GetEnvironmentVariable("APP_URL") ?? "http://localhost:5000");
Assert.True(await page.Locator("h1").IsVisibleAsync());
}
}Mehr dazu findest du direkt bei Playwright.
Wann laufen Smoke- bzw. UI-Tests? Idealerweise Post-Deployment auf einem definierten Environment (Test/Staging) als Gate. Das ist euer Sicherheitsnetz nach dem Deployment. Damit das zuverlässig ist, brauchst du stabile Testdaten und idempotente Runs.
Performance-, Security- und Architekturtests: Die Non-Functional-Suite sinnvoll integrieren
Nicht-funktionale Tests sind oft die ersten, die später gemacht werden. Leider sind sie es oft, die dich später am meisten kosten. Der Trick ist, sie pragmatisch zu implementieren, statt sie entweder zu ignorieren oder sie ständig laufen zu lassen.
Performance
Performance Tests sind ein wichtiger Baustein, um die Stabilität und Skalierbarkeit einer Anwendung sicherzustellen. Microbenchmarks helfen dabei, gezielt Hotspots im Code zu identifizieren und Regressionen frühzeitig zu erkennen.
Für aussagekräftige Load- und Stresstests ist es jedoch entscheidend, dass die Testumgebung möglichst produktionsnah ist, andernfalls sind die Ergebnisse oft wenig belastbar. Die Häufigkeit solcher Tests richtet sich nach Risiko und Aufwand: Häufig werden sie nach Bedarf durchgeführt, etwa vor Releases oder nach größeren Änderungen. Bei klaren Risiken oder Performance-Zielen können sie auch regelmäßig, beispielsweise als Nightly oder wöchentlich, eingeplant werden.
Einen guten Überblick zu Load- und Stresstests bietet Microsoft unter ASP.NET Core load/stress testing.
Security
Security Tests sollten fester Bestandteil jeder Pipeline sein. Dazu zählen SCA (Software Composition Analysis) für Abhängigkeits- und Lizenzprüfungen, Secret Scanning, SAST (Static Application Security Testing) und DAST (Dynamic Application Security Testing). Schnelle Checks wie SCA und SAST lassen sich effizient bereits im Pull Request integrieren und bieten so frühzeitiges Feedback.
Zur Generierung und Prüfung von Abhängigkeiten (SCA) kann unser Beitrag Governance: Software Bill of Materials (SBOM) weiterhelfen. Wer nach Secrets im Code sucht, findet in Secrets im Source Code – unterschätztes Risiko mit echten Folgen eine gute Lösung.
Aufwändigere DAST-Scans sind meist als Nightly-Job oder nach dem Deployment sinnvoll, da sie eine laufende Anwendung voraussetzen und mehr Zeit benötigen. Die Frequenz und Tiefe der Security-Tests sollte sich immer an Kosten und Risiko orientieren, um einen guten Kompromiss zwischen Sicherheit und Geschwindigkeit zu erreichen.
Wenn du DAST pragmatisch integrieren willst, ist OWASP ZAP ein etabliertes Tool. Dazu gibt es auch einen Lunaris-Beitrag: Automatisierter Web Security Check mit OWASP ZAP.
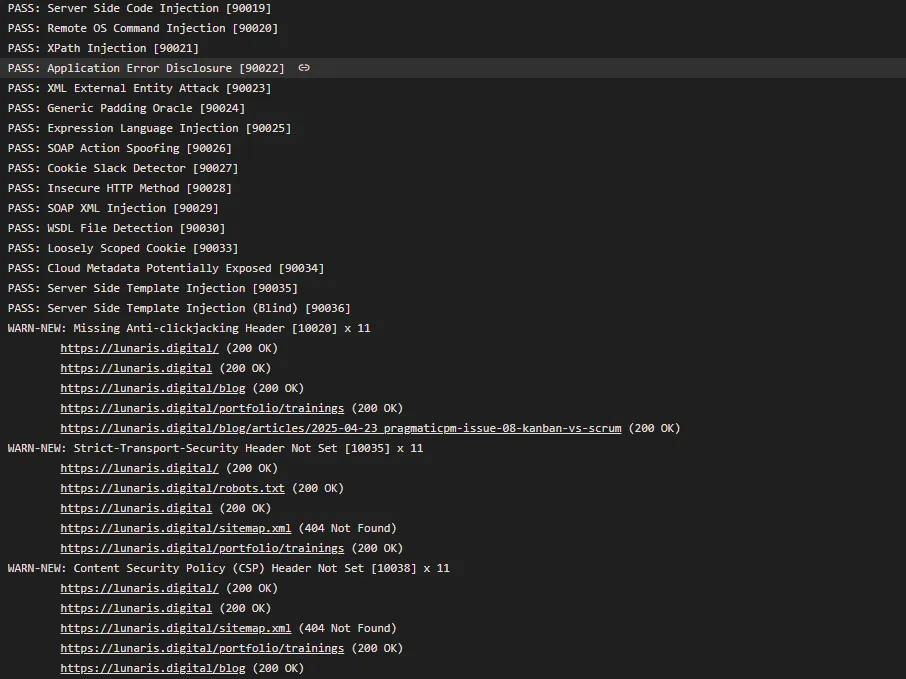
Architekturtests
Architekturtests sind automatisierte Regeln gegen Verstöße an das Design der Architektur oder Namenskonventionen. Diese versuchen zu verhindern, dass sich unerwünschte Abhängigkeiten einschleichen (z.B. UI-Schicht greift direkt auf DB zu). Aber sie helfen auch, wenn du z.B. eine modulare Architektur mit klaren Grenzen verfolgst.
Sie ergänzen Code Reviews, ersetzen sie aber nicht. Wenn du tiefer einsteigen willst, schau in unseren Artikel: Architekturtests mit ArchUnitNet.
using static ArchUnitNET.Fluent.ArchRuleDefinition;
var noDependencyFromServiceToUI =
Classes().That().ResideInNamespace("MyProject.Service")
.Should().NotDependOnAny(Classes().That().ResideInNamespace("MyProject.UI"));
noDependencyFromServiceToUI.Check(architecture);Naming, Testdaten, Coverage
Wenn du willst, dass Tests skalieren (Team wächst, Codebase wächst), brauchst du Standards. Nicht als Dogma, sondern als gemeinsame Basis für Qualität.
Naming & Struktur
- Testprojekte nach Typ:
.UnitTests,.IntegrationTests,.ContractTests,.UiTests. - Testklassen nach getesteter Klasse.
- Testmethoden konsistent:
Given_When_ThenoderMethod_Scenario_Expected. - Markierungen/Tags, um Tests selektiv laufen zu lassen.
Testdaten-Strategie
- Nutze Builders/Factories statt Copy-Paste.
- Zufallsdaten nur mit festem Seed oder deterministischer Generierung verwenden, damit Tests reproduzierbar bleiben.
- Wiederverwendbare Datensätze für Unit/Contract/Integration, aber ohne versteckte Kopplungen.
Mit versteckten Kopplungen ist gemeint: Testdaten sollten nicht implizit voraussetzen, dass Tests in einer bestimmten Reihenfolge laufen oder dass ein anderer Test vorher Daten vorbereitet hat. Besser sind klar isolierte Fixtures pro Testtyp und idempotente Setups.
Coverage richtig einordnen
Coverage ist ein Signal, kein Qualitätsbeweis. Microsoft sagt das sehr deutlich in den Unit testing best practices: 95% ist nicht automatisch besser als 85%, wenn die letzten Prozent nur triviale oder künstliche Tests sind. Fokussiere auf kritische Pfade, und schließe Generated Code gezielt aus.
Mutation Testing kann helfen, die Aussagekraft der Coverage zu erhöhen. Dabei wird die Implementierung gezielt verändert (z.B. eine if-Bedingung negiert), um zu prüfen, ob vorhandene Tests diese künstlichen Fehler (Mutationen) erkennen. Schlagen die Tests bei solchen Mutationen nicht fehl, decken sie die Logik zwar formal ab, prüfen aber nicht wirklich das Verhalten. Tools wie Stryker.NET für .NET oder StrykerJS für JavaScript/TypeScript machen das automatisiert und geben ein Mutation Score-Feedback, das oft ehrlicher ist als reine Coverage-Prozente.
Dabei muss aber bedacht werden, dass Mutation Testing zusätzlichen Aufwand bedeutet und die Testlaufzeiten verlängern kann. Es ist also eher ein ergänzendes Werkzeug für kritische Module als etwas, das du flächendeckend einsetzen solltest.
Nicht jeder Code muss gecovered sein: Es ist sinnvoll, generierten Code, DTOs, Migrations, Prototypen oder rein technische Hilfsfunktionen explizit von der Coverage auszuschließen. Das sorgt dafür, dass die Coverage-Zahl sich auf den wirklich relevanten, fachlichen Code bezieht.
Coverage-Reports aufbereiten: Für die Auswertung und Visualisierung von Coverage-Daten ist ReportGenerator ein sehr hilfreiches Tool. Es kann verschiedene Coverage-Formate (z.B. von Coverlet, OpenCover, Cobertura) zusammenführen und als übersichtliche HTML-Reports oder Badges für die CI/CD-Pipeline ausgeben. So sieht das Team auf einen Blick, wo noch Lücken sind und kann gezielt nachbessern, statt nur auf eine Prozentzahl zu optimieren.
Fast Feedback, aber mit Sicherheitsnetz
Wenn du dir aus diesem Beitrag nur eine Sache mitnimmst, dann diese: Eine gute Testing-Strategie optimiert nicht auf maximale Coverage, sondern auf schnelles, verlässliches Feedback entlang des gesamten Delivery-Prozesses.
Starte mit klaren Definitionen, trenne Testtypen sauber und plane die Ausführung nach Kosten und Risiko. Wenn eure PRs schnell sind, Nightlies sinnvoll Tiefe abdecken und Post-Deployment ein kleines Sicherheitsnetz steht, wird Testing vom Bremsklotz zum Beschleuniger.
Ein weiterer, oft unterschätzter Vorteil einer klaren Testing-Strategie: Du kannst sie direkt in GenAI Prompts und Agents als Guardrail verwenden. Das Ziel ist nicht für Copilot zu schreiben, sondern Regeln so klar zu machen, dass Mensch und Tool sie befolgen können.
Wie sieht eure Testing-Strategie aus, und welche Testtypen laufen bei euch wann? Schau gerne bei uns auf LinkedIn vorbei und diskutiere mit.
Autoren

Florian Bader
Florian ist Solution Architect und Microsoft Most Valuable Professional (MVP) für Azure & Azure IoT mit langjähriger Erfahrung im Bereich DevOps, Cloud und Digitalisierung. Er unterstützt Unternehmen dabei, effiziente und effektive Lösungen zu entwickeln, die ihre digitalen Projekte nachhaltig zum Erfolg führen.
Verwandte Beiträge
Weitere Artikel zu ähnlichen Themen.

Playwright: Moderne UI-Tests für Webanwendungen in .NET

Unit Testing in .NET: Saubere Tests für sauberen Code
Von Swagger UI zu Scalar: Praktischer Einstieg für .NET APIs
Logging Redaction in .NET und im Browser – Sensible Daten sicher aus Logs entfernen
Produktiv lokal entwickeln: Weniger Setup, mehr Fokus
Style matters: Wie du Codeformatierung im Team richtig aufziehst
Sicherheitsrelevante Daten in .NET richtig schützen – Kein Platz für Hardcoding
Security: Automatisierter Web Security Check mit OWASP ZAP