
Wenn das Deployment schiefläuft: Fehlerstrategien und Best Practices
Software auszuliefern bedeutet heute weit mehr als nur einen Knopf zu drücken. Moderne Anwendungen bestehen aus vielen Komponenten wie Frontend, Backend, Infrastruktur und Datenbanken. Jede dieser Komponenten bringt eigene Herausforderungen mit sich. Ein fehlerhaftes Deployment kann zu Ausfällen führen, Datenverlust verursachen oder die Nutzererfahrung erheblich beeinträchtigen.
In komplexen Systemlandschaften reicht es nicht aus, den Deployment-Prozess zu automatisieren. Es ist ebenso wichtig, Strategien zu entwickeln, um auf Fehler angemessen reagieren zu können. Fehler gehören zum Alltag in der Softwareentwicklung. Entscheidend ist, wie man mit ihnen umgeht.
Wie kann sichergestellt werden, dass Deployments auch in schwierigen Situationen gelingen? Im Folgenden werden bewährte und moderne Ansätze vorgestellt, mit denen Software zuverlässig, flexibel und kontrolliert ausgeliefert werden kann und wie dabei auch auf unerwartete Probleme vorbereitet wird.
Was beim Deployment schiefgehen kann
Ein Deployment ist immer ein Eingriff in ein laufendes System. Dabei können Fehler auf verschiedenen Ebenen auftreten. Häufige Ursachen sind fehlerhafter Code, falsche Konfigurationen, nicht getestete Abhängigkeiten oder Probleme mit der Infrastruktur. Auch Datenbankänderungen können zu Inkonsistenzen führen, wenn sie nicht sauber geplant und umgesetzt werden.
Nicht alle Komponenten sind gleich kritisch. Ein Fehler im Frontend kann oft schnell behoben werden und betrifft meist nur die Darstellung. Ein Fehler im Backend kann dagegen zu fehlerhaften Datenverarbeitungen führen. Besonders kritisch sind Änderungen an der Datenbank, da sie meist dauerhaft sind und sich schwer rückgängig machen lassen. Einmal ausgeführte Migrationen wie das Löschen von Spalten oder das Anpassen von Datentypen beeinflussen direkt die gespeicherten Daten und die Struktur. Im Gegensatz zu Code oder Infrastruktur, die oft einfach zurückgesetzt werden können, sind Datenbankänderungen häufig irreversibel und fehlerhafte Migrationen können zu Datenverlust oder Inkonsistenzen führen.
Automatisierte Tests helfen dabei, viele dieser Fehler frühzeitig zu erkennen. Unit-Tests, Integrationstests und End-to-End-Tests sind wichtige Werkzeuge, um die Qualität eines Releases sicherzustellen. Dennoch gibt es immer wieder Situationen, in denen ein Fehler erst nach dem Deployment sichtbar wird. Für diesen Fall braucht es eine solide Strategie, um schnell und kontrolliert reagieren zu können.
Die Kritikalität einer Komponente bestimmt, wie vorsichtig man beim Deployment vorgehen sollte. Während man eine Anwendung oft problemlos zurückrollen kann, erfordert die Infrastruktur meist ein vollständiges Re-Provisioning. Bei Datenbanken ist ein Rollback oft gar nicht möglich, sodass hier besonders sorgfältige Strategien notwendig sind.
Ein gutes Verständnis dieser Unterschiede ist die Grundlage für den gezielten Einsatz von Fehlerstrategien, die im nächsten Abschnitt vorgestellt werden.
Fehlerstrategien im Deployment
Es gibt verschiedene Strategien, die je nach Systemarchitektur und Komponententyp eingesetzt werden können.
Rollback
Eine der wichtigsten Strategien, um nach einem fehlerhaften Deployment schnell zu reagieren, ist das sogenannte Rollback. Doch was genau bedeutet das? Beim Rollback wird ein System gezielt auf einen früheren, stabilen Zustand zurückgesetzt. Ziel ist es, die durch das fehlerhafte Deployment verursachten Probleme nicht erst zu analysieren oder zu reparieren, sondern durch das Zurücksetzen auf eine bekannte, funktionierende Version unmittelbar zu neutralisieren.. Rollbacks sind damit ein zentrales Werkzeug, um die Auswirkungen von Problemen zu begrenzen und den Geschäftsbetrieb abzusichern.
Fix and Roll Forward
Statt einen Rollback durchzuführen, wird bei einem Roll Forward versucht, den Fehler direkt zu beheben und eine neue, korrigierte Version bereit zu stellen. Ein Roll Forward kann sich lohnen, wenn die Fehlerursache klar ist und sich schnell beheben lässt. Andernfalls ist der vermeintliche Vorteil gegenüber einem Rollback schnell dahin. Diese Strategie ist besonders bei Continuous Delivery sinnvoll, da sie den Fluss nicht unterbricht. Voraussetzung ist, dass die Ursache schnell identifiziert und behoben werden kann. Ein gutes Monitoring und eine klare Fehlerdiagnose sind hier entscheidend.
Feature deaktivieren
Wenn ein neues Feature Probleme verursacht, kann es gezielt deaktiviert werden. Feature Flags ermöglichen es, Funktionen unabhängig vom Code zu steuern. So lässt sich ein Fehler schnell isolieren, ohne dass ein vollständiges Rollback notwendig ist. Feature Flags sind besonders nützlich, um neue Funktionen schrittweise einzuführen und bei Problemen schnell zu reagieren. Sie erlauben es, Features dynamisch zu aktivieren oder zu deaktivieren, ohne dass ein neuer Deployment-Prozess angestoßen werden muss. So kann ein fehlerhaftes Feature sofort abgeschaltet werden, während der Rest des Systems weiterläuft. Feature Flags sollten jedoch mit Bedacht eingesetzt werden, da sie zusätzliche Komplexität in den Code einbringen können. Es ist wichtig, dass sie gut dokumentiert und getestet sind, um Missverständnisse zu vermeiden. Jedes Feature Flag ist ein kleines Stück technische Schuld, das im Code verbleibt, bis es entfernt wird. Deshalb sollten sie regelmäßig überprüft und aufgeräumt werden.
Traffic umleiten oder isolieren
Bei größeren Systemen kann der Traffic gezielt gesteuert werden. Canary Releases und Blue-Green Deployments erlauben es, neue Versionen zunächst nur einem kleinen Teil der Nutzer bereitzustellen. Wenn Probleme auftreten, kann der Traffic sofort zurück auf die stabile Version gelenkt werden. Auch Circuit Breaker helfen dabei, fehlerhafte Komponenten automatisch zu isolieren und so den Gesamtausfall zu verhindern.
Komponenten-spezifische Strategien
Nicht jede Komponente eines Systems lässt sich gleich behandeln. Anwendungen, Infrastruktur und Datenbanken unterscheiden sich in ihrer Kritikalität, ihrer Änderbarkeit und den verfügbaren Fehlerstrategien. Deshalb lohnt sich ein gezielter Blick auf jede dieser Bereiche.
Anwendungen
Bei Anwendungen ist ein Rollback meist unkompliziert. Eine vorherige Version kann oft schnell wiederhergestellt werden, z.B. in dem die Pipeline der vorherigen Version einfach noch einmal neu ausgeführt wird. Bei Anwendungen, die containerisiert sind oder über Deployment Slots bereitgestellt werden, kann relativ einfach auf eine alte Version geändert werden. Moderne Plattformen wie Azure oder Kubernetes unterstützen diese Ansätze besonders gut.
Feature Flags eignen sich besonders für Anwendungen, da sie ad-hoc über Konfigurationen gesteuert werden können, ohne dass ein neuer Deployment-Prozess angestoßen werden muss. Azure App Service propagiert Konfigurationen über Environment Variables, die von der Anwendung konsumiert werden können. Allerdings ist dafür meist ein Neustart der Anwendung notwendig. Flexibler sind spezialisierte Dienste wie Azure App Configuration oder LaunchDarkly, die Feature Flags zentral verwalten und Änderungen sofort an die Anwendung weitergeben können. So lassen sich Features sicher und dynamisch aktivieren oder deaktivieren.
Sowohl Azure App Service mit seinen Deployment Slots, als auch Azure Kubernetes Service (AKS) und Azure Container Apps bieten die Möglichkeit, ein Canary- oder Blue-Green-Deployment umzusetzen. Dazu wird definiert, welcher Anteil des Traffics auf die neu ausgelieferte Version geleitet wird. Dies kann auch voll automatisch über Azure Pipelines umgesetzt werden. Dazu wird die Pipeline so konfiguriert, dass sie nach dem Deployment automatisch prüft, ob die neue Version stabil ist. Anhand von Metriken und Alerts leitet diese automatisch nach und nach mehr Traffic auf die neue Version um, sofern alles stabil ist.
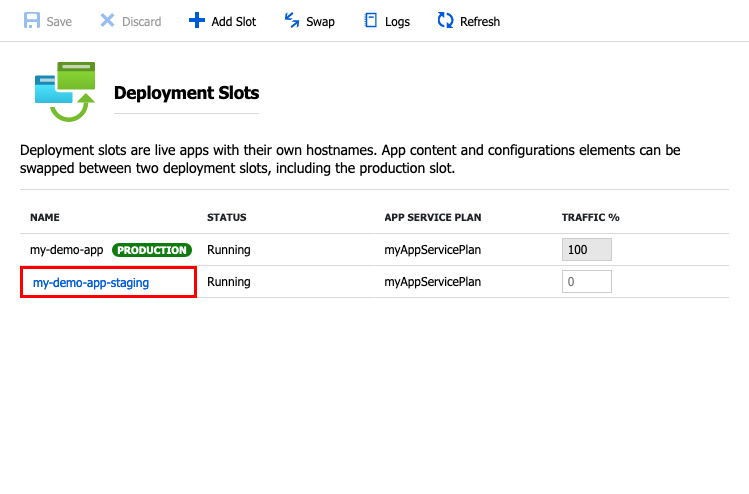
Source: Microsoft Learn
Infrastruktur
Die Infrastruktur ist oft schwerer zu ändern als die Anwendung selbst. Änderungen an Servern, Netzwerken oder Cloud-Ressourcen können weitreichende Auswirkungen haben. Infrastructure as Code (IaC) hilft dabei, Änderungen nachvollziehbar und reproduzierbar zu machen. Tools wie Terraform, Pulumi oder Bicep ermöglichen es, Infrastrukturänderungen versioniert und automatisiert auszurollen. Ein Rollback erfolgt hier nicht durch das Zurückspielen eines alten Zustands, sondern durch das erneute Ausrollen einer vorherigen Konfiguration.
Da bei einem Rollback aber unter Umständen Resourcen gelöscht oder neu angelegt werden müssen, was je nach Resource etwas dauern kann, empfiehlt sich hier meist ein Roll Forward. Dies muss aber von Fall zu Fall entschieden werden. Dazu ist es auch wichitg, dass die Infrastruktur in sinnvolle Einheiten unterteilt ist, die unabhängig voneinander ausgerollt werden können. So lassen sich Änderungen gezielt auf einzelne Komponenten anwenden, ohne das gesamte System zu beeinflussen.
Datenbanken
Datenbanken stellen beim Deployment die größte Herausforderung dar. Änderungen sind oft dauerhaft und lassen sich nicht einfach zurücknehmen, da sie direkt die gespeicherten Daten und deren Struktur beeinflussen. Ein fehlerhaftes Datenbank-Deployment kann zu Datenverlust oder Inkonsistenzen führen, die sich nur mit großem Aufwand korrigieren lassen. Denn niemand will eine Point-In-Time-Wiederherstellung durchführen, nur weil eine Migration fehlerhaft war und dabei im Zweifel Daten verlieren oder mühsam von einem Backup die Daten wiederherstellen.
Deshalb ist hier besondere Vorsicht geboten. Versionierte Migrationen mit Tools wie Entity Framework Core helfen dabei, Änderungen nachvollziehbar und kontrolliert auszurollen. Dennoch sollte jede Migration sorgfältig getestet werden, idealerweise in einer Umgebung mit realistischen Daten. Denn nichts ist schlimmer als eine Strukturänderung die auf Staging funktioniert, aber auf Production zu einem Fehler führt, da hier Daten als Edge Case vorliegen, die es auf Staging nicht gibt.
Eine bewährte Strategie ist die parallele Struktur. Dabei wird eine neue Tabelle mit geänderter Struktur angelegt, in die neue Daten geschrieben werden. Alte Daten werden im Hintergrund schrittweise migriert. Erst wenn die neue Struktur stabil ist, wird die alte Tabelle entfernt. So lässt sich ein Rollback durchführen, ohne die Datenbank direkt zurückzusetzen, da in der alten Tabelle weiterhin Daten liegen, die bei Bedarf wieder verwendet werden können.
-- Alte Tabelle (v1)
CREATE TABLE Products (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Amount DECIMAL(10,2)
);
-- Neue Tabelle (v2) mit Breaking Change: 'Amount' wird zu 'Price', und ein neues Pflichtfeld 'Currency' kommt hinzu
CREATE TABLE ProductsV2 (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Price DECIMAL(10,2) NOT NULL,
Currency CHAR(3) NOT NULL
);
-- Trigger auf der alten Tabelle, der bei jedem Insert auch in die neue Tabelle schreibt
CREATE TRIGGER trg_Products_Insert
AFTER INSERT ON Products
FOR EACH ROW
BEGIN
INSERT INTO ProductsV2 (Id, Name, Price, Currency)
VALUES (NEW.Id, NEW.Name, NEW.Amount, 'EUR'); -- Standardwährung als Beispiel
END;Dieses Beispiel zeigt, wie eine neue Tabelle mit geänderter Struktur parallel zur alten betrieben werden kann. Ein Trigger sorgt dafür, dass neue Einträge automatisch in die neue Struktur übernommen werden. So können Daten schrittweise migriert und die neue Struktur getestet werden, bevor die alte Tabelle entfernt wird. Solange gilt aber ebenfalls wie bei Feature Flags, dass die alte Tabelle eine technische Schuld darstellt, die nach erfolgreicher Migration aufgeräumt werden sollte.
Auch bei Datenbanken gilt: Änderungen sollten möglichst rückwärtskompatibel sein. Neue Spalten können hinzugefügt werden, ohne bestehende Abfragen zu stören. So bleibt das System auch bei schrittweisen Änderungen stabil. Das gilt natürlich nur, wenn nicht blind ein SELECT * gemacht wird, was aus Performancegründen ohnehin unterlassen werden sollte.
Breaking Changes, wie das Entfernen von Spalten oder das Ändern von Datentypen, sollten vermieden werden, da sie ein Rollback erheblich erschweren können. Hier gilt umso mehr: Eine sorgfältige Planung und umfassende Tests sind unerlässlich, um die Integrität der Datenbank zu gewährleisten.
Wer keine relationale Datenbank sondern eine NoSQL-Datenbank wie MongoDB oder Cosmos DB verwendet, sollte ebenfalls auf Migrationen setzen. Diese Datenbanken bieten oft eigene Mechanismen, um Änderungen an der Struktur kontrolliert auszurollen. Siehe hierzu die Schema Versionierung von CosmosDB als einen Ansatz.
Strategien zur Risikominimierung
Ein sicheres Deployment beginnt lange vor dem eigentlichen Ausrollen. Wer Risiken minimieren will, muss den gesamten Prozess durchdenken und geeignete Schutzmaßnahmen etablieren. Dabei helfen sowohl organisatorische als auch technische Strategien.
Mehrstufige Environments
Der Einsatz von getrennten Umgebungen wie Entwicklung, Test, Staging und Produktion ist ein bewährter Ansatz. Jede Umgebung dient einem klaren Zweck und ermöglicht es, Änderungen schrittweise zu validieren. In der Staging-Umgebung kann das System unter realistischen Bedingungen getestet werden, bevor es produktiv geht. So lassen sich viele Fehler frühzeitig erkennen und beheben. Das setzt natürlich voraus, dass die Staging-Umgebung so nah wie möglich an der Produktionsumgebung ist, um realistische Tests zu ermöglichen.
Deployment Ringe
Deployment Ringe sind eine Erweiterung des Staging-Konzepts. Hier wird die neue Version zunächst nur einem kleinen, kontrollierten Nutzerkreis bereitgestellt, zum Beispiel internen Mitarbeitern oder ausgewählten Testkunden. Erst wenn keine Probleme auftreten, wird die Version schrittweise für weitere Gruppen freigegeben. Diese Strategie reduziert das Risiko und ermöglicht schnelles Feedback aus der Praxis. Deployment Ringe können sowohl als eigene Umgebung aber auch über Strategien wie Canary Releases oder Blue-Green Deployments umgesetzt werden.
Monitoring und automatische Rollbacks
Ein gutes Monitoring ist unverzichtbar, um Fehler nach dem Deployment schnell zu erkennen. Metriken wie Fehlerquoten, Antwortzeiten oder Systemauslastung geben Hinweise auf mögliche Probleme. In Kombination mit automatisierten Rollback-Mechanismen kann das System bei kritischen Fehlern selbstständig auf eine stabile Version zurückschalten. So bleibt die Verfügbarkeit erhalten, auch wenn etwas schiefläuft.
In Azure Pipelines gibt es die Möglichkeit über Post-Deployment Checks genau diese Metriken nach einem Deployment vollautomatisch abzufragen. So kann entweder ein Rollback ausgelöst werden, oder aber eine Benachrichtigung an das Team gesendet werden, um schnell reagieren zu können. Auch kann so ein Deployment in weitere Umgebungen blockiert werden, wenn die Metriken nicht den Erwartungen entsprechen. So wird sichergestellt, dass nur stabile Versionen weiter ausgerollt werden.
API- und Datenbank-Versionierung
Versionierung ist ein zentrales Werkzeug, um Systeme unabhängig voneinander weiterentwickeln und ausrollen zu können. Sie ermöglicht es, neue Funktionen bereitzustellen, ohne bestehende Integrationen zu stören. Besonders bei der Kommunikation zwischen Frontend und Backend sowie bei Datenbankänderungen spielt sie eine entscheidende Rolle.
Eine sauber versionierte API erlaubt es, neue Funktionen einzuführen, ohne bestehende Clients zu brechen. So kann das Backend aktualisiert oder zurückgerollt werden, während ältere Frontends weiterhin funktionieren. Es gibt verschiedene Strategien zur API-Versionierung, die wir bereits in unserem Blogpost Web API: Versioning ausführlich behandelt haben.
Aber nicht nur APIs sollten versioniert werden. Auch Datenbanken profitieren von einer klaren Versionierung. Hierbei muss das Backend die Möglichkeit besitzen, mit verschiedenen Datenbankversionen umzugehen. Frameworks wie Entity Framework Core liefern eine Möglichkeit direkt in der Datenbank um zu prüfen, welche Migrationen bereits angewendet wurden und auch welche Version die Datenbankstruktur aktuell hat. So kann das Backend gezielt auf die aktuelle Datenbankversion reagieren und sicherstellen, dass alle Abfragen und Operationen korrekt ausgeführt werden.
var currentVersion = await _context.Database
.SqlQueryRaw<Version>("SELECT ProductVersion FROM __EFMigrationsHistory ORDER BY MigrationId DESC LIMIT 1")
.FirstOrDefaultAsync();
if (currentVersion >= new Version("8.0.6"))
{
var product = await QueryProductMethodA();
}
else
{
var product = await QueryProductMethodB();
}Auch hier gilt dasselbe wie bei Feature Flags: Diese Art der Logik sollte aufgeräumt werden, sobald die Migrationen abgeschlossen sind. Das Backend sollte nicht dauerhaft auf verschiedene Datenbankversionen reagieren müssen, da dies den Code unnötig kompliziert macht.
Wichtig hierbei: Die Anwendung sollte niemals die Datenbank-Migrationen durchführen. Sonst kann ein unabhängiges Deployment von Anwendung und Datenbank nicht durchgeführt werden.
Best Practices und Empfehlungen
Ein erfolgreiches Deployment ist kein Zufall, sondern das Ergebnis klarer Prozesse, technischer Standards und guter Kommunikation.
Automatisierte Deployments sind der Schlüssel zu reproduzierbaren und sicheren Releases. Continuous Integration und Continuous Delivery sorgen dafür, dass Änderungen regelmäßig getestet und ausgerollt werden. Build-Pipelines sollten alle Schritte vom Code-Check-in bis zur produktiven Bereitstellung abbilden – inklusive Tests, Code-Analyse und Sicherheitsprüfungen. So kann im Zweifel bei einem Problem ein Roll Forward schnell und kontrolliert durchgeführt werden.
Technische Maßnahmen allein reichen nicht aus. Ein erfolgreiches Deployment braucht klare Kommunikation. Alle Beteiligten sollten wissen, wann ein Deployment stattfindet, welche Änderungen enthalten sind und wie im Fehlerfall reagiert wird. Ein gemeinsames Verständnis für Risiken und Abläufe erhöht die Reaktionsgeschwindigkeit und reduziert Unsicherheiten.
Jede Änderung sollte eine dokumentierte Rückfallstrategie haben. Das betrifft nicht nur den Code, sondern auch Infrastruktur und Datenbankmigrationen. Im Fehlerfall muss klar sein, wie ein Rollback durchgeführt wird, welche Daten betroffen sind und welche Schritte notwendig sind. Eine gute Dokumentation spart im Ernstfall wertvolle Zeit.
Eine hohe Testabdeckung ist essenziell, um Fehler frühzeitig zu erkennen. Neben Unit- und Integrationstests sollten auch Migrations-Tests für Datenbankänderungen etabliert werden. Diese simulieren reale Szenarien und prüfen, ob Daten korrekt übernommen und verarbeitet werden. Besonders bei komplexen Datenstrukturen lohnt sich ein automatisierter Testlauf vor jedem Deployment.
Fazit
Ein sicheres Deployment erfordert mehr als nur technische Werkzeuge. Es braucht ein tiefes Verständnis für die unterschiedlichen Komponenten eines Systems, deren Kritikalität und die möglichen Fehlerquellen. Anwendungen lassen sich oft einfach zurückrollen, Infrastruktur muss reproduzierbar sein und Datenbanken verlangen besondere Vorsicht.
Strategien wie Rollback, Feature Flags, Canary Releases und Versionierung helfen dabei, flexibel und kontrolliert auf Fehler zu reagieren. Automatisierung, Monitoring und klare Kommunikation im Team sind ebenso entscheidend wie eine gute Vorbereitung und Dokumentation.
Wer Deployment als strategischen Bestandteil der Softwareentwicklung versteht, kann Risiken minimieren und gleichzeitig die Geschwindigkeit und Qualität der Auslieferung erhöhen.
Welche Deployment-Strategien haben sich in euren Projekten bewährt? Schau gerne bei uns auf LinkedIn vorbei und teile Deine Erfahrungen mit uns.
Autoren

Florian Bader
Florian ist Solution Architect und Microsoft Most Valuable Professional (MVP) für Azure & Azure IoT mit langjähriger Erfahrung im Bereich DevOps, Cloud und Digitalisierung. Er unterstützt Unternehmen dabei, effiziente und effektive Lösungen zu entwickeln, die ihre digitalen Projekte nachhaltig zum Erfolg führen.
Verwandte Beiträge
Weitere Artikel zu ähnlichen Themen.

Azure Container Apps für .NET: Wann ACA statt App Service oder AKS?
Bicep in der Praxis: Module, Teamstandards, Governance und Deployment für Entwicklerteams
Von Azure Pipelines zu GitHub Actions: Was es zu beachten gibt

Schnellere CI-Builds: Git Checkout gezielt optimieren

CRA & Updates: Welche Mechanismen sich für welche Produkte eignen

Managed Identity in Azure: Auth ohne Secrets

Abhängigkeiten im Griff: Private Feeds für NuGet, npm, pip und Docker
Branching-Strategien für Long-Term-Support und CRA-Compliance
