
Proaktiv statt reaktiv: Monitoring und Alerting in Azure richtig aufsetzen
Monitoring sorgt dafür, dass Systeme stabil laufen und Fehler früh erkannt werden. In vielen Projekten wird Monitoring erst dann ernst genommen, wenn Probleme auftreten. Häufig sind Alerts zu spät oder fehlen, Dashboards sind überladen und die Ursachenanalyse kostet wertvolle Zeit.
Azure bietet viele Werkzeuge, um Anwendungen und Infrastruktur zu überwachen und Probleme frühzeitig zu erkennen. Visualisierung und automatisiertes Alerting ergänzen sich. Nur zu beobachten reicht nicht, nur zu alarmieren ohne Kontext führt zu Unsicherheit. Ziel ist eine sinnvolle Kombination beider Ansätze.
In diesem Artikel erfährst du, wie du Monitoring und Alerting in Azure effektiv einsetzt. Es geht um zentrale und dezentrale Strategien, rollenbasierte Anforderungen, sinnvolle Visualisierungen und hilfreiche Alerts. Außerdem werden typische Fallstricke, Kosten und Empfehlungen behandelt. Ziel ist, Monitoring als festen Bestandteil von Entwicklung und Betrieb zu verstehen.
Monitoring-Strategien: zentral oder dezentral
Bevor man sich mit konkreten Tools und Visualisierungen beschäftigt, lohnt sich ein Blick auf die grundsätzliche Architektur des Monitorings. In Azure lassen sich Monitoring-Strategien grob in zentral und dezentral unterteilen. Beide Ansätze haben ihre Berechtigung und sollten abhängig von der Struktur des Teams und der Anwendung gewählt werden.
Ein zentralisiertes Monitoring bündelt alle Daten an einem Ort. Dashboards, Logs und Alerts werden übergreifend verwaltet, oft durch ein Plattform- oder Infrastrukturteam. Dieser Ansatz eignet sich besonders gut, wenn mehrere Anwendungen gemeinsam betrieben werden oder wenn Compliance-Anforderungen eine einheitliche Sicht auf den Systemzustand verlangen. Die zentrale Verwaltung erleichtert auch die Pflege von Standards, etwa bei Schwellenwerten für Alerts oder bei der Visualisierung von Metriken.
Ein dezentraler Ansatz erlaubt es einzelnen Teams, ihr Monitoring selbst zu gestalten. Sie definieren eigene Dashboards, Alerts und Workbooks, die genau auf ihre Anwendung und ihre Arbeitsweise zugeschnitten sind. Das erhöht die Flexibilität und fördert die Eigenverantwortung. Gleichzeitig kann es zu Inkonsistenzen kommen, wenn keine gemeinsamen Standards existieren.
Empfehlenswert ist oft ein hybrider Ansatz. Die Infrastruktur stellt zentrale Komponenten bereit, etwa ein zentrales Log Analytics Workspace oder ein gemeinsames Grafana-Dashboard für den Überblick. Die einzelnen Teams ergänzen diese Basis mit eigenen Visualisierungen und Alert-Regeln, die auf ihre spezifischen Anforderungen abgestimmt sind. So entsteht ein Monitoring-System, das sowohl Übersicht als auch Detailtiefe bietet und sich an die unterschiedlichen Rollen und Verantwortlichkeiten im Unternehmen anpasst.
Visualisierung: Überblick, Analyse und Tiefe
Visualisierung ist der erste Schritt, um den Zustand von Anwendungen und Infrastruktur verständlich darzustellen. Azure bietet dafür mehrere Werkzeuge, die unterschiedliche Anforderungen abdecken. Dashboards eignen sich besonders für den schnellen Überblick. Sie zeigen aggregierte Metriken, Statusanzeigen und KPIs, die auf einen Blick erfassbar sind. Dabei sollten sie rollenbasiert gestaltet sein, damit Entwicklung, Ops und Support jeweils die für sie relevanten Informationen sehen.
Für tiefere Analysen sind Azure Workbooks eine gute Wahl. Sie ermöglichen interaktive Visualisierungen, kombinieren Metriken und Logs und erlauben exploratives Arbeiten mit den Daten. Workbooks sind besonders hilfreich, wenn man Zusammenhänge verstehen oder Ursachen für Auffälligkeiten finden möchte. Auch die Möglichkeit, Filter und Parameter zu setzen, macht sie zu einem flexiblen Werkzeug für die Analyse.
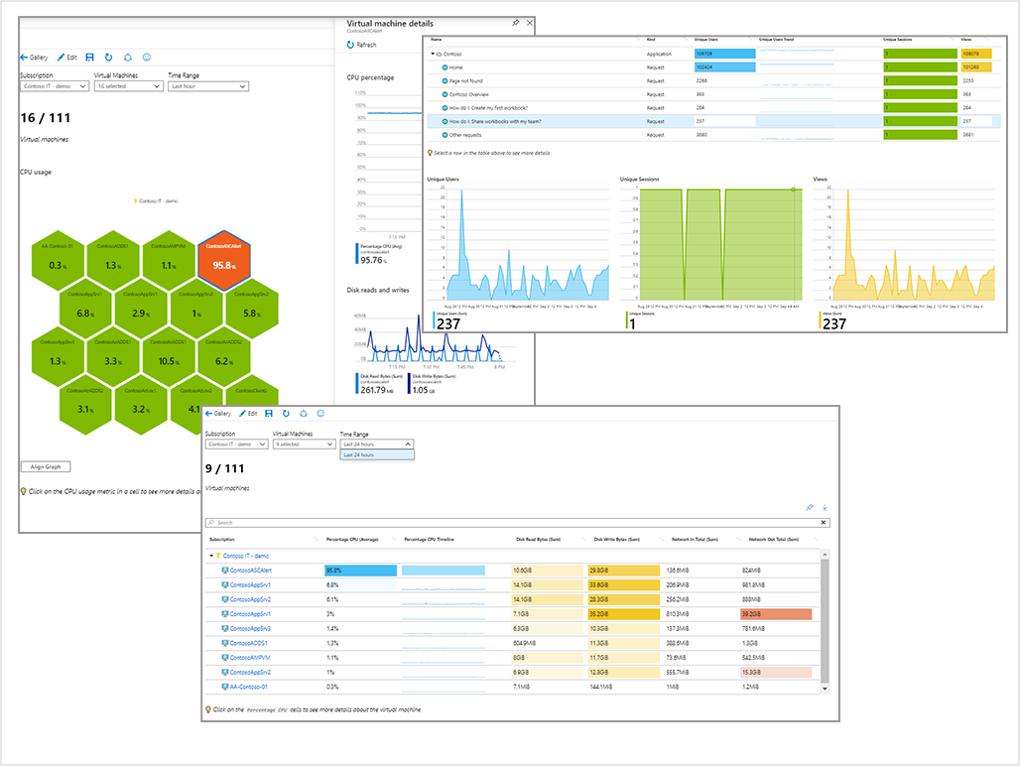
Source: Microsoft Learn
Azure Metrics Explorer und Log Analytics bieten gezielte Auswertungen. Metriken sind ideal für Performance- und Zustandsdaten, während Logs detaillierte Informationen zu Ereignissen und Fehlern liefern. Beide Quellen lassen sich kombinieren, um ein vollständiges Bild zu erhalten. Dabei ist es wichtig, die richtigen Datenquellen zu wählen und die Abfragen effizient zu gestalten, da die Nutzung von Log Analytics nach Datenvolumen und Abfragehäufigkeit abgerechnet wird.
Azure Managed Grafana ergänzt diese Werkzeuge als zentrales Visualisierungstool mit hoher Flexibilität. Es erlaubt die Integration verschiedenster Datenquellen, darunter Azure Monitor, Log Analytics, Application Insights, Prometheus und viele weitere. Grafana eignet sich besonders gut, wenn mehrere Systeme überwacht werden oder wenn ein einheitliches Dashboard über verschiedene Plattformen hinweg benötigt wird. Gleichzeitig bietet Grafana die Möglichkeit, Dashboards individuell auf Teams zuzuschneiden. Die Konfiguration erfolgt über eine intuitive Oberfläche oder per YAML/JSON, was auch die Versionierung und Wiederverwendung erleichtert.

Source: Microsoft Learn
Auch Power BI kann eine sinnvolle Alternative oder Ergänzung zur Visualisierung in Azure sein. Power BI eignet sich besonders, wenn komplexe Berichte, interaktive Dashboards oder die Integration von Monitoring-Daten mit weiteren Geschäftsdaten gefragt sind. Es bietet leistungsstarke Möglichkeiten zur Datenmodellierung, erlaubt die Verbindung verschiedenster Quellen (inklusive Azure Monitor und Log Analytics) und unterstützt die gemeinsame Nutzung von Berichten im Unternehmen. Power BI ist ideal, wenn Monitoring nicht nur für technische Teams, sondern auch für Management und Fachbereiche transparent und verständlich aufbereitet werden soll. Die Integration in Microsoft 365 und die Möglichkeit, Berichte automatisiert zu aktualisieren, machen Power BI zu einem flexiblen Werkzeug für organisationsweite Transparenz.
Rollenbasierte Anforderungen an Monitoring
Monitoring ist nicht für alle gleich. Je nach Rolle im Team unterscheiden sich die Anforderungen an Visualisierung, Detailtiefe und Reaktionsgeschwindigkeit deutlich. Ein gutes Monitoring-System berücksichtigt diese Unterschiede und bietet gezielte Ansichten und Alerts für die jeweiligen Aufgabenbereiche.
Die Entwicklung benötigt vor allem Einblick in die technische Funktionsweise der Anwendung. Sie interessieren sich für Performance-Metriken, Fehlerprotokolle, Auslastung einzelner Komponenten und die Möglichkeit, Logs gezielt zu durchsuchen. Für sie sind Azure Workbooks und Log Analytics besonders hilfreich, da sie explorative Analysen und gezielte Abfragen ermöglichen.
Support-Teams hingegen brauchen eine schnelle Übersicht über den aktuellen Zustand der Anwendung. Sie müssen erkennen können, ob ein Dienst verfügbar ist, ob Nutzer betroffen sind und ob es bekannte Störungen gibt. Dashboards mit klaren Statusanzeigen, einfache Alerts und die Integration in Kommunikationskanäle wie Microsoft Teams sind hier besonders wertvoll.
Die Verantwortlichen für Betrieb konzentrieren sich auf Infrastruktur, Ressourcenverbrauch und Systemzustände. Für diese Rolle sind Metriken zur CPU-Auslastung, Speichernutzung, Netzwerkverbindungen und Skalierungsverhalten entscheidend. Auch die Integration mit automatisierten Reaktionen, etwa über Azure Automation oder Logic Apps, spielt hier eine wichtige Rolle.
Ein Monitoring-System sollte diese Unterschiede nicht ignorieren. Statt ein einziges Dashboard für alle bereitzustellen, ist es sinnvoll, gezielte Ansichten zu erstellen, die auf die jeweiligen Rollen zugeschnitten sind. So wird vermieden, dass wichtige Informationen untergehen oder unnötige Details die Übersicht erschweren.
Grenzen und Fallstricke bei Dashboards
Dashboards sind ein zentrales Werkzeug im Monitoring, aber sie sind nicht automatisch hilfreich. Ihre Qualität hängt stark davon ab, wie sie gestaltet sind und wie gut sie zur jeweiligen Zielgruppe passen. Ein häufiges Problem ist die Überfrachtung mit Informationen. Wenn zu viele Metriken, Diagramme und Statusanzeigen gleichzeitig dargestellt werden, verliert man schnell den Überblick. Statt Klarheit entsteht Verwirrung.
Auch die visuelle Gestaltung spielt eine große Rolle. Farben sollten konsistent und intuitiv verwendet werden. Rot steht für Fehler, Gelb für Warnungen und Grün für Normalzustand – das ist etabliert und sollte nicht willkürlich verändert werden. Wenn Farben falsch oder uneinheitlich eingesetzt werden, kann das zu Fehlinterpretationen führen.
Ein weiteres Problem ist die fehlende Möglichkeit, in die Tiefe zu gehen. Ein Dashboard, das nur aggregierte Werte zeigt, hilft wenig, wenn ein Problem auftritt. Es sollte immer möglich sein, von der Übersicht in eine detaillierte Analyse zu wechseln, etwa durch Verlinkung zu Logs, Workbooks oder spezifischen Metrik-Abfragen.
Dashboards sollten außerdem kontextsensitiv sein. Ein Entwickler braucht andere Informationen als ein Support-Mitarbeiter oder ein Administrator. Wenn alle dieselbe Ansicht nutzen müssen, ist sie für niemanden wirklich hilfreich. Besser ist es, gezielte Dashboards zu erstellen, die auf die jeweiligen Rollen und Aufgaben zugeschnitten sind.
Ein gutes Dashboard ist klar, fokussiert und interaktiv. Es zeigt relevante Informationen, erlaubt gezielte Analysen und unterstützt schnelle Entscheidungen. Alles andere ist nur eine bunte Oberfläche ohne echten Mehrwert.
Alerting: Proaktiv statt reaktiv
Während Dashboards dabei helfen, den Zustand eines Systems zu beobachten, sind Alerts das Mittel, um aktiv auf Probleme aufmerksam gemacht zu werden. Sie ergänzen die Visualisierung durch automatisierte Benachrichtigungen, die bei bestimmten Bedingungen ausgelöst werden. So erfährt man nicht erst durch Nutzerfeedback oder manuelle Kontrolle von einem Fehler, sondern kann frühzeitig reagieren.
Azure bietet mit Azure Monitor Alerts ein flexibles System, um Schwellenwerte, Ereignisse oder Log-Abfragen zu überwachen. Auch Azure Managed Grafana unterstützt Alerting, entweder direkt über Panels oder über integrierte Regeln. Beide Systeme erlauben es, Bedingungen zu definieren, unter denen ein Alarm ausgelöst wird. Dabei kann man zwischen Metrik-basierten Alerts, Log-basierten Alerts und Aktivitätsüberwachung unterscheiden.
Ein wichtiger Aspekt für nachhaltiges Monitoring und Alerting ist die Definition beider Komponenten über Infrastructure as Code (IaC). So werden Alerts und Dashboards nicht nur dokumentiert, sondern können als wiederverwendbare Templates für weitere Anwendungen dienen und flexibel angepasst werden. Azure Monitor Alerts lassen sich direkt über ARM Templates, Bicep oder Terraform konfigurieren und versionieren. Für Azure Managed Grafana steht ein eigener Terraform Provider sowie eine REST API zur Verfügung, die auch in Azure genutzt werden kann. Dadurch wird die Einrichtung und Pflege von Monitoring und Alerting nachvollziehbar, automatisierbar und konsistent über verschiedene Umgebungen hinweg.
resource cpuAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = {
name: 'AppServicePlanCpuHighAlert'
location: location
properties: {
description: 'Alert when App Service Plan CPU >= 90%'
severity: 2 // Warnung
enabled: true
scopes: [
appServicePlan.id
]
evaluationFrequency: 'PT5M' // Alle 5 Minuten prüfen
windowSize: 'PT15M' // Überprüfungszeitraum von 15 Minuten
criteria: { // Wenn CPU-Auslastung über 90% für 15 Minuten
allOf: [
{
name: 'HighCpu'
metricName: 'CpuPercentage'
metricNamespace: 'Microsoft.Web/serverfarms'
operator: 'GreaterThanOrEqual'
threshold: 90
timeAggregation: 'Average' // Durchschnitt über den Zeitraum, sinnvoll wäre auch Maximum für Spikes
dimensions: []
}
]
}
actions: [] // Hier könnten Aktionen wie E-Mail, Webhook oder Teams-Benachrichtigungen definiert werden
autoMitigate: true // Automatisches Beheben des Alerts bei Erfüllung der Gegenbedingungen (z.B. wenn CPU wieder unter 90% fällt)
}
}Ein zentraler Aspekt ist die Klassifizierung von Alerts nach Kritikalität. Nicht jeder Alarm erfordert sofortiges Eingreifen. Eine sinnvolle Einteilung in Informationsmeldungen, Warnungen, Fehler und kritische Zustände hilft dabei, Prioritäten zu setzen und unnötige Unterbrechungen zu vermeiden. Alerts sollten so gestaltet sein, dass sie nicht ignoriert werden, aber auch nicht zur Belastung werden.
Das Phänomen der Alert Fatigue tritt auf, wenn zu viele oder schlecht konfigurierte Alerts ausgelöst werden. Die Folge ist, dass wichtige Meldungen übersehen oder bewusst ignoriert werden. Um das zu vermeiden, sollten Schwellenwerte regelmäßig überprüft, Regeln konsolidiert und die Relevanz jeder Benachrichtigung hinterfragt werden.
Auch die Kosten spielen eine Rolle. Azure stellt ein Freikontingent für einfache Alerts bereit, danach entstehen Kosten abhängig von der Prüffrequenz und der Anzahl der Checks insbesondere bei häufigen Metrik- oder Log-Abfragen. Wer viele komplexe Alerts nutzt, sollte das Abrechnungsmodell kennen. Ein Vorteil von Azure Managed Grafana ist, dass die Kosten nicht pro Alert, sondern pro Grafana-Instanz berechnet werden. So können beliebig viele Alerts erstellt werden, ohne dass zusätzliche Kosten pro Alert entstehen.
Ein gut konfiguriertes Alerting-System ist ein entscheidender Bestandteil eines stabilen Betriebs. Es ersetzt nicht die Visualisierung, sondern ergänzt sie durch gezielte Hinweise, die zum richtigen Zeitpunkt an die richtigen Personen gehen.
Alert-Zielsysteme und Integration
Ein Alert ist nur dann hilfreich, wenn er die richtigen Personen zur richtigen Zeit erreicht. Azure bietet verschiedene Möglichkeiten, um Benachrichtigungen zu versenden. Dazu gehören klassische Kanäle wie E-Mail, aber auch moderne Integrationen wie Microsoft Teams, Webhooks oder ITSM-Systeme. Die Wahl des Zielsystems hängt von der Arbeitsweise des Teams und der Kritikalität des Alarms ab.
Für operative Teams ist eine direkte Integration in Kommunikationsplattformen wie Teams besonders effektiv. Alerts erscheinen dort, wo ohnehin gearbeitet wird, und können sofort kommentiert oder weitergeleitet werden. Hierbei sei erwähnt, dass man an die meisten Chat-Systeme wie Microsoft Teams auch eine E-Mail-Adresse anbinden kann, um Alerts direkt dorthin zu senden. Diese Integration ermöglicht es, Alerts dort zu empfangen, wo das Team ohnehin kommuniziert. So werden sie nicht übersehen und können direkt bearbeitet werden. Für automatisierte Prozesse lassen sich Webhooks nutzen, die Alerts an andere Systeme weiterleiten oder Aktionen auslösen. Auch die Anbindung an Incident-Management-Plattformen wie ServiceNow oder PagerDuty ist möglich und sinnvoll, wenn strukturierte Eskalationspfade benötigt werden.
Wichtig ist, dass Alerts nicht nur technisch zugestellt werden, sondern auch sinnvoll klassifiziert und priorisiert sind. Ein kritischer Fehler sollte sofort auffallen und eine Reaktion auslösen. Eine Warnung kann dokumentiert und später analysiert werden. Informationsmeldungen sollten nicht stören, aber verfügbar sein. Die Zustellung sollte sich an diesen Kategorien orientieren, damit die Aufmerksamkeit dort liegt, wo sie gebraucht wird.
Die Integration von Alerts in bestehende Kommunikations- und Betriebsprozesse erhöht die Reaktionsgeschwindigkeit und verbessert die Zusammenarbeit. Sie macht Monitoring nicht nur sichtbar, sondern handlungsfähig.
Eine gute Umgebung ist kein Zufall
Monitoring und Alerting sind mehr als technische Pflicht. Sie sind die Grundlage für Stabilität, Transparenz und schnelle Reaktionsfähigkeit in modernen Cloud-Umgebungen. Wer sich frühzeitig mit den richtigen Werkzeugen, sinnvollen Visualisierungen und klaren Alert-Regeln beschäftigt, schafft nicht nur Sicherheit im Betrieb, sondern auch Vertrauen in die eigene Architektur.
Azure bietet eine breite Palette an Möglichkeiten, um den Zustand von Anwendungen und Infrastruktur sichtbar und steuerbar zu machen. Von Dashboards über Workbooks bis hin zu automatisierten Alerts und Health Checks lässt sich ein System aufbauen, das sowohl Überblick als auch Tiefe bietet. Die Kunst liegt darin, diese Werkzeuge gezielt einzusetzen, sie auf Rollen und Anforderungen abzustimmen und sie als Teil eines kontinuierlichen Prozesses zu verstehen.
Monitoring ist kein einmaliges Setup, sondern ein integraler Bestandteil von Entwicklung, Betrieb und Qualitätssicherung. Wer es als Teil seiner DevOps-Strategie denkt, profitiert langfristig von mehr Stabilität, weniger Überraschungen und besserer Zusammenarbeit im Team.
Wie setzt ihr Monitoring und Alerting in euren Azure-Projekten aktuell ein und an welchen Stellen besteht aus eurer Sicht noch Potenzial, um schneller, gezielter oder zuverlässiger auf Probleme zu reagieren? Schau gerne bei uns auf LinkedIn vorbei und teile Deine Erfahrungen mit uns.
Autoren

Florian Bader
Florian ist Solution Architect und Microsoft Most Valuable Professional (MVP) für Azure & Azure IoT mit langjähriger Erfahrung im Bereich DevOps, Cloud und Digitalisierung. Er unterstützt Unternehmen dabei, effiziente und effektive Lösungen zu entwickeln, die ihre digitalen Projekte nachhaltig zum Erfolg führen.
Verwandte Beiträge
Weitere Artikel zu ähnlichen Themen.
Agentic Ops mit Grafana und GitHub: Vom Alert zur Erstanalyse
